BENCHMARKING WOLFSSL AND WOLFCRYPT
The wolfSSL embedded SSL/TLS library was written from the ground-up with portability, performance, and memory usage in mind. Here you will find a collection of existing benchmark information for wolfSSL and the wolfCrypt cryptography library as well as information on how to benchmark wolfSSL on your own platform. If you would like additional benchmark data or have any questions about your specific platform, please contact us at info@wolfssl.com.
wolfCrypt Benchmark Application
Many users are curious about how the wolfSSL embedded SSL/TLS library will perform on a specific hardware device or in a specific environment. Because of the wide variety of different platforms and compilers used today in embedded, enterprise, and cloud-based environments, it is hard to give generic performance calculations.
To help wolfSSL users and customers in determining performance for wolfSSL and wolfCrypt, a benchmark application is bundled with wolfSSL. Because the underlying cryptography is a very performance-critical aspect of SSL/TLS, our benchmark application runs performance tests on wolfCrypt’s algorithms.
The benchmark utility is located in the “./wolfcrypt/benchmark” directory of the wolfSSL package. After building wolfSSL and the associated examples and apps, the benchmark application can be run by issuing the following command from the package directory root:
./wolfcrypt/benchmark/benchmark
Typical output will look similar to the output below (showing throughput in MB/s as well as cycles per byte):
wolfCrypt Benchmark (block bytes 1048576, min 1.0 sec each) RNG 100 MB took 1.047 seconds, 95.466 MB/s Cycles per byte = 22.92 AES-128-CBC-enc 200 MB took 1.020 seconds, 196.027 MB/s Cycles per byte = 11.16 AES-128-CBC-dec 215 MB took 1.008 seconds, 213.318 MB/s Cycles per byte = 10.26 AES-192-CBC-enc 175 MB took 1.016 seconds, 172.265 MB/s Cycles per byte = 12.70 AES-192-CBC-dec 180 MB took 1.009 seconds, 178.405 MB/s Cycles per byte = 12.27 AES-256-CBC-enc 150 MB took 1.007 seconds, 148.932 MB/s Cycles per byte = 14.69 AES-256-CBC-dec 160 MB took 1.026 seconds, 155.994 MB/s Cycles per byte = 14.03 AES-128-GCM-enc 60 MB took 1.010 seconds, 59.427 MB/s Cycles per byte = 36.82 AES-128-GCM-dec 65 MB took 1.070 seconds, 60.750 MB/s Cycles per byte = 36.02 AES-192-GCM-enc 60 MB took 1.050 seconds, 57.138 MB/s Cycles per byte = 38.30 AES-192-GCM-dec 60 MB took 1.024 seconds, 58.590 MB/s Cycles per byte = 37.35 AES-256-GCM-enc 55 MB took 1.029 seconds, 53.438 MB/s Cycles per byte = 40.95 AES-256-GCM-dec 60 MB took 1.090 seconds, 55.069 MB/s Cycles per byte = 39.74 CHACHA 360 MB took 1.001 seconds, 359.628 MB/s Cycles per byte = 6.09 CHA-POLY 285 MB took 1.014 seconds, 280.943 MB/s Cycles per byte = 7.79 MD5 450 MB took 1.010 seconds, 445.573 MB/s Cycles per byte = 4.91 POLY1305 1265 MB took 1.000 seconds, 1264.402 MB/s Cycles per byte = 1.73 SHA 475 MB took 1.000 seconds, 474.914 MB/s Cycles per byte = 4.61 SHA-224 210 MB took 1.018 seconds, 206.308 MB/s Cycles per byte = 10.61 SHA-256 210 MB took 1.018 seconds, 206.200 MB/s Cycles per byte = 10.61 SHA-384 280 MB took 1.016 seconds, 275.520 MB/s Cycles per byte = 7.94 SHA-512 275 MB took 1.000 seconds, 274.868 MB/s Cycles per byte = 7.96 SHA3-224 240 MB took 1.006 seconds, 238.506 MB/s Cycles per byte = 9.18 SHA3-256 225 MB took 1.007 seconds, 223.454 MB/s Cycles per byte = 9.79 SHA3-384 175 MB took 1.002 seconds, 174.610 MB/s Cycles per byte = 12.53 SHA3-512 125 MB took 1.031 seconds, 121.254 MB/s Cycles per byte = 18.05 HMAC-MD5 445 MB took 1.001 seconds, 444.651 MB/s Cycles per byte = 4.92 HMAC-SHA 470 MB took 1.009 seconds, 465.749 MB/s Cycles per byte = 4.70 HMAC-SHA224 200 MB took 1.001 seconds, 199.874 MB/s Cycles per byte = 10.95 HMAC-SHA256 205 MB took 1.004 seconds, 204.228 MB/s Cycles per byte = 10.72 HMAC-SHA384 290 MB took 1.009 seconds, 287.401 MB/s Cycles per byte = 7.61 HMAC-SHA512 290 MB took 1.013 seconds, 286.214 MB/s Cycles per byte = 7.65 RSA 2048 public 2800 ops took 1.014 sec, avg 0.362 ms, 2761.995 ops/sec RSA 2048 private 300 ops took 1.308 sec, avg 4.359 ms, 229.402 ops/sec DH 2048 key gen 735 ops took 1.001 sec, avg 1.361 ms, 734.608 ops/sec DH 2048 key agree 800 ops took 1.123 sec, avg 1.404 ms, 712.131 ops/sec ECC 256 key gen 1108 ops took 1.001 sec, avg 0.903 ms, 1107.306 ops/sec ECDHE 256 agree 1200 ops took 1.043 sec, avg 0.869 ms, 1150.329 ops/sec ECDSA 256 sign 1200 ops took 1.078 sec, avg 0.898 ms, 1113.279 ops/sec ECDSA 256 verify 1700 ops took 1.045 sec, avg 0.615 ms, 1627.064 ops/sec
This application is especially useful for comparing the public key speed before and after changing the math library. You can test the results using the normal math library (./configure), the fastmath library (./configure --enable-fastmath), and the fasthugemath library (./configure --enable-fasthugemath).
Memory Usage
Footprint sizes (compiled binary size) for wolfSSL range between 20-100kB depending on build options and the compiler being used. Typically on an embedded system with an embedded and optimized compiler, build sizes will be around 60kB. This will include a full-featured TLS 1.2 client and server. For details on build options and ways to further customize wolfSSL, please see Chapter 2 of the CyaSSL Manual, or the wolfSSL Tuning Guide.
Regarding runtime memory usage, wolfSSL will generally consume between 1-36 kB per SSL/TLS session. The RAM usage per connection will vary depending the size of the input/output buffers being used, public key algorithm, and key size. The I/O buffers in wolfSSL default to 128 bytes and are controlled by the RECORD_SIZE define in ./wolfssl/internal.h. The maximum size is 16 kB per buffer (as specified by the SSL/TLS RFC). As an example, with standard 16kB buffers, the total runtime memory usage of wolfSSL with a single connection would be 3kB (the library) + 16kB (input buffer) + 16kB (output buffer) = around 35kB.
The TLS context (WOLFSSL_CTX) is shared between all TLS connections of either a client or server. The runtime memory usage can vary depending on how many certificates are being loaded and what size the certificate files are. It will also vary depending on the session cache and whether or not storing session certificates is turned on (--enable-session-certs). If you are concerned with reducing the session cache size, you can define SMALL_SESSION_CACHE (reduce the default session cache from 33 session to 6 sessions) and save almost 2.5 kB. You can disable the session cache by defining NO_SESSION_CACHE, reducing memory by nearly 3 kB.
Reference Benchmarks
As we port wolfSSL to various platforms, we oftentimes conduct benchmarks on these platforms. Below you will find a collection of some of those benchmarks for reference. If you have benchmarked wolfSSL on a specific platform, please send us your benchmark numbers (with specific platform and library configuration) and we’ll add them to the list!
Platform:
Benchmark:
Platform:
Microchip PIC32MZ:
PIC32MZ, at 200MHz
Benchmark:
Benchmarks were collected using PIC32MZ Ethernet Starter Kit, using the wolfCrypt benchmark application and compiled with MPLAB X.
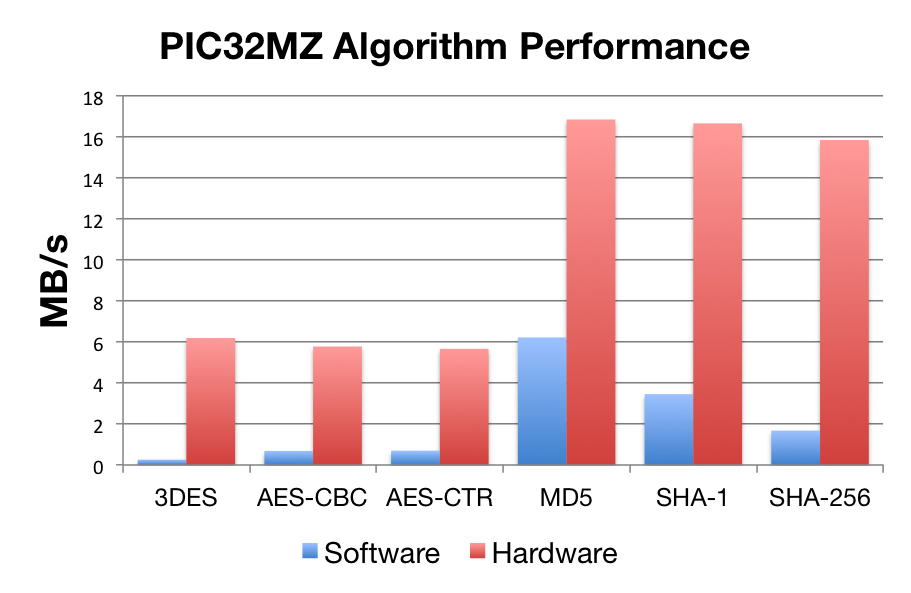
| Software Crypto | Hardware Crypto | |
| AES-CBC | 0.26 Mb/s | 5.78 Mb/s |
| AES-CTR | 0.69 Mb/s | 5.67 Mb/s |
| 3DES | 6.19 Mb/s | 6.19 Mb/s |
| MD5 | 6.22 Mb/s | 16.84 Mb/s |
| SHA-1 | 3.46 Mb/s | 16.65 Mb/s |
| SHA-256 | 1.678 Mb/s | 15.84 Mb/s |
Reference:
Platform:
STM32:
STM32F439, at 180MHz
STM32F756, at 216MHz
Benchmark:
Benchmarks were collected using STMicro Evaluation Boards, using the wolfCrypt benchmark application and compiled with IAR EWARM (Optimization: High/Size).
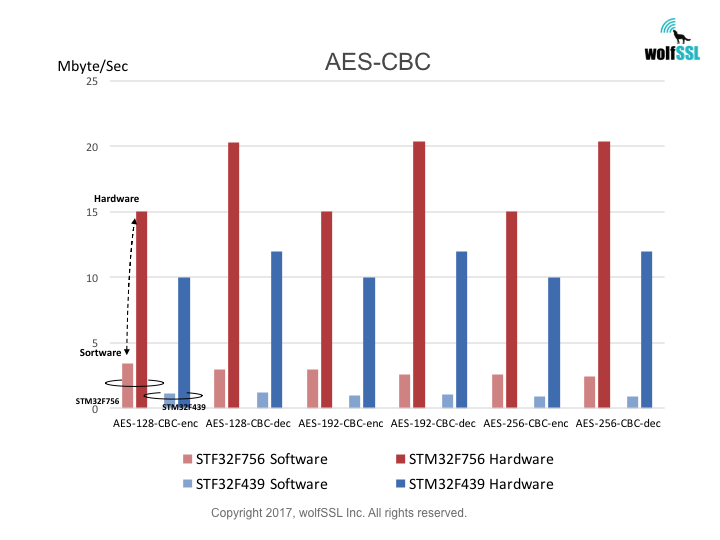
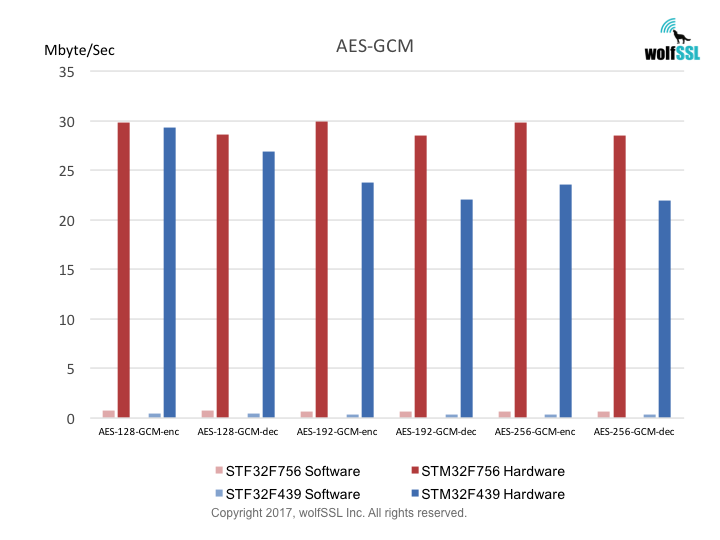
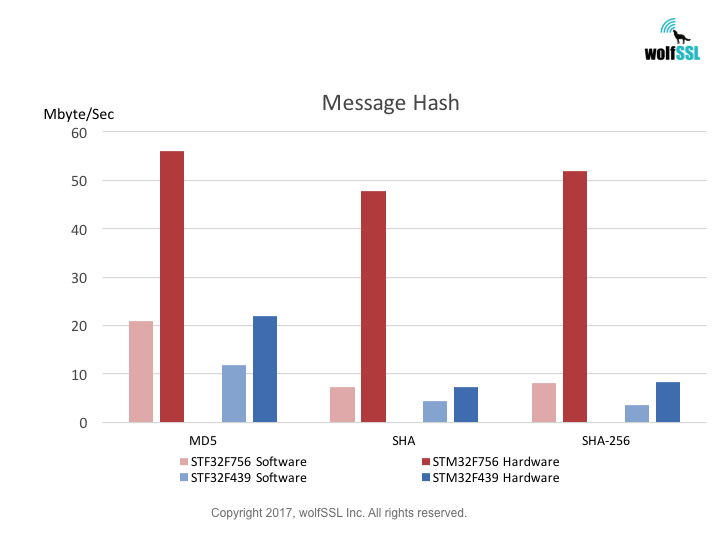
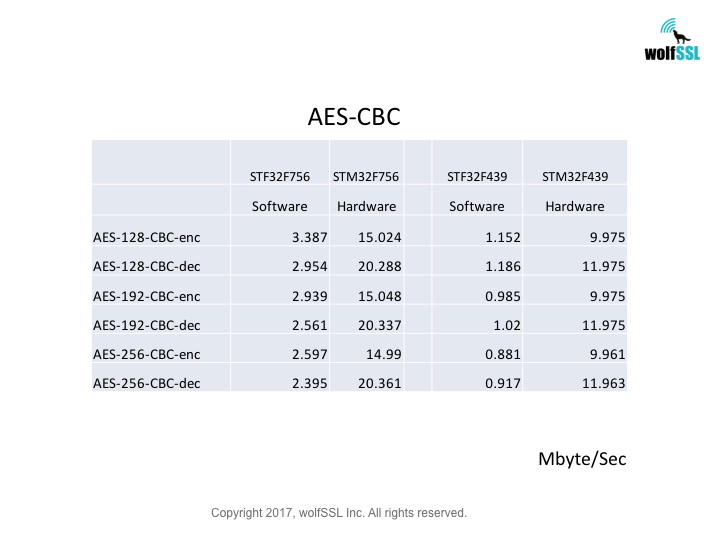
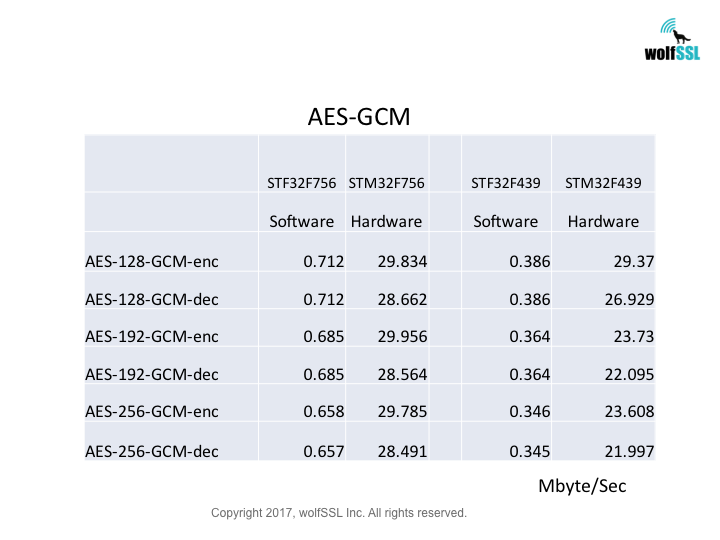
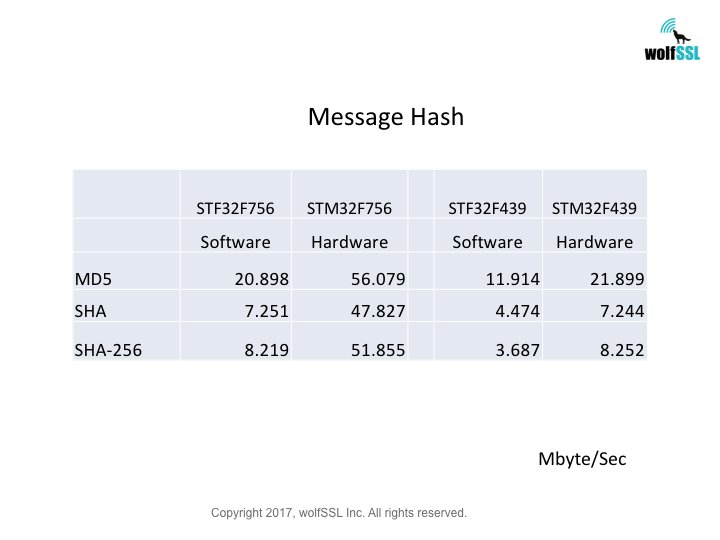
Reference:
Platform:
STM32F777NI:
ARM Cortex M7
216 MHz
Using GCC ARM (arm-none-eabi-gcc) with OpenSTM32 (System Workbench)
Bare Metal
Benchmark:
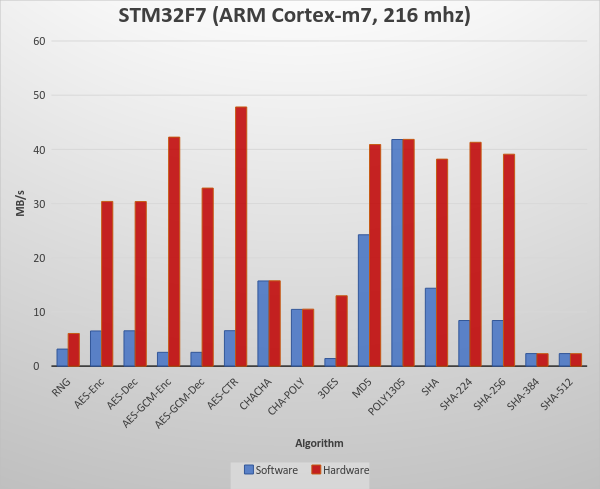
Crypto Benchmarks:
wolfSSL Software Crypto, Normal Big Integer Math Library
| RNG | 3 MB took 1.000 seconds | 3.149 MB/s |
| AES-Enc | 6 MB took 1.000 seconds | 6.494 MB/s |
| AES-Dec | 7 MB took 1.000 seconds | 6.519 MB/s |
| AES-GCM-Enc | 3 MB took 1.004 seconds | 553 MB/s |
| AES-GCM-Dec | 3 MB took 1.004 seconds | 2.553 MB/s |
| AES-CTR | 7 MB took 1.000 seconds | 6.543 MB/s |
| CHACHA | 16 MB took 1.000 seconds | 15.723 MB/s |
| CHA-POLY | 10 MB took 1.000 seconds | 10.474 MB/s |
| 3DES | 1 MB took 1.008 seconds | 1.405 MB/s |
| MD5 | 24 MB took 1.000 seconds | 24.243 MB/s |
| POLY1305 | 42 MB took 1.000 seconds | 41.821 MB/s |
| SHA | 14 MB took 1.000 seconds | 14.380 MB/s |
| SHA-224 | 8 MB took 1.000 seconds | 8.423 MB/s |
| SHA-256 | 8 MB took 1.000 seconds | 8.423 MB/s |
| SHA-384 | 2 MB took 1.000 seconds | 2.319 MB/s |
| SHA-512 | 2 MB took 1.000 seconds | 2.319 MB/s |
STM32F7 Hardware Crypto, Normal Big Integer Math Library
| RNG | 6 MB took 1.000 seconds | 6.030 MB/s |
| AES-Enc | 30 MB took 1.000 seconds | 30.396 MB/s |
| AES-Dec | 30 MB took 1.000 seconds | 30.371 MB/s |
| AES-GCM-Enc | 42 MB took 1.000 seconds | 42.261 MB/s |
| AES-GCM-Dec | 33 MB took 1.000 seconds | 32.861 MB/s |
| AES-CTR | 48 MB took 1.000 seconds | 47.827 MB/s |
| CHACHA | 16 MB took 1.000 seconds | 15.747 MB/s |
| CHA-POLY | 11 MB took 1.000 seconds | 10.522 MB/s |
| 3DES | 13 MB took 1.000 seconds | 12.988 MB/s |
| MD5 | 41 MB took 1.000 seconds | 40.894 MB/s |
| POLY1305 | 42 MB took 1.000 seconds | 41.846 MB/s |
| SHA | 38 MB took 1.004 seconds | 38.202 MB/s |
| SHA-224 | 41 MB took 1.000 seconds | 41.309 MB/s |
| SHA-256 | 39 MB took 1.000 seconds | 39.111 MB/s |
| SHA-384 | 2 MB took 1.004 seconds | 2.310 MB/s |
| SHA-512 | 2 MB took 1.004 seconds | 2.310 MB/s |
Reference:
Platform:
Apple A11 Bionic
2.39 GHz hexa-core 64-bit
Benchmark:
Benchmarks on Apple’s new A11 processor in their latest iPhone 8 / 8 Plus and iPhone X. This processor features six ARMv8 CPU cores (2 high-performance 2.53GHz and 4 high-efficiency 1.42GHz). The benchmarks use wolfSSL’s latest speedups for ARMv8 crypto extensions and single precision math to demonstrate our exceptional performance.
For symmetric AES and SHA using our ARMv8 crypto assembly speedups we see:
AES-128 CBC Encrypt: 912.347 MB/s (36.58X) AES-128 CBC Decrypt: 6,084.83 MB/s (256.15X) AES-128 GCM Encrypt: 1,242.28 MB/s (193.65X) AES-128 GCM Decrypt: 575.83 MB/s (90.26X) SHA-256: 1,717.28 MB/s (56.11X)
This feature is enabled using `./configure –enable-armasm` or the `WOLFSSL_ARMASM` define.
For asymmetric RSA, DH and ECC using our single precision math speedups we see:
RSA 2048 public: 1,211.27 ops/sec (1.50X) RSA 2048 private: 32.59 ops/sec (1.18X) DH 2048 key gen: 77.44 ops/sec (1.24X) DH 2048 key agree: 77.45 ops/sec (1.29X) ECC 256 key gen: 1670.65 ops/sec (8.67X) ECDHE 256 agree: 396.88 ops/sec (2.05X) ECDSA 256 sign: 1,212.33 ops/sec (6.42X) ECDSA 256 verify: 331.02 ops/sec (2.38X)
This feature is enabled using `./configure –enable-sp` or the `WOLFSSL_HAVE_SP_RSA`, `WOLFSSL_HAVE_SP_DH` and `WOLFSSL_HAVE_SP_ECC` defines.
For TLS v1.2 we see the following performance benchmarks by cipher suite:
DHE-RSA-AES128-SHA256: CPS 22.5, Read 388 MB/s, Write 106 MB/s ECDHE-RSA-AES128-GCM-SHA256: CPS 26.2, Read 598 MB/s RX, Write 125 MB/s ECDHE-ECDSA-AES128-GCM-SHA256: CPS 83.4, Read 504.8 MB/s, Write 92.2 MB/s
Benchmarks done on iPhone X using a single thread and our wolfCrypt and wolfSSL benchmark tools.
`X`= performance increase as compared to our default software based implementation.
`CPS` = Connections per second
You can download the raw benchmark numbers here:
https://www.wolfssl.com/files/benchmarks/iOSiPhoneXA11Benchmarks.pdf
Reference
wolfSSL Blog Post
Platform:
Benchmark:

Benchmarks of wolfCrypt running in an Intel SGX enclave. These benchmarks show that running wolfCrypt cryptography inside SGX has minimal performance impact on cryptography operation.
Non-SGX Benchmarks
SHA-256 0.264s 189.078 MB/s
AES-GCM 3.142s 15.911 MB/s
RSA (2048) Encrypt 0.238 ms
RSA (2048) Decrypt 6.239 ms
SGX Benchmarks, Inside the Enclave
SHA-256 0.263s 190.436 MB/s -0.38% difference
AES-GCM 3.128s 15.985 MB/s -0.45% difference
RSA (2048) Encrypt 0.245 ms 2.94% difference
RSA (2048) Decrypt 6.242 ms 0.05% difference
Reference
Platform:
Benchmark:
Crypto Benchmarks:
Benchmarks using wolfSSL’s asynchronous benchmark application running multiple threads with CPU affinity in user space:
RSA 2048 public: 209,909 ops/sec
RSA 2048 private: 41,999 ops/sec
DH 2048 key gen: 112,491 ops/sec
DH 2048 key agree: 95,129 ops/sec
ECDHE 256 agree: 55,117 ops/sec
ECDSA 256 sign: 46,798 ops/sec
ECDSA 256 verify: 28,917 ops/sec
AES-CBC Enc: 2,932 MB/s
AES-CBC Dec: 2,882 MB/s
AES-GCM: 2,903 MB/s
3DES: 1,511 MB/s
MD5: 2,309 MB/s
SHA: 5,068 MB/s
SHA-224: 2,392 MB/s
SHA-256: 1,275 MB/s
SHA-384: 2,020 MB/s
SHA-512: 1,908 MB/s
Reference
Platform:
HiKey LeMaker
Kirin 620 SoC
ARM® CortexTM-A53 Octa-core 64-bit up to 1.2GHz (ARM v8 instruction set)
8GB eMMC storage
1GB RAM
Benchmark:

Platform:
AVX1: 1.8GHz, Intel Core i5
AVX2: Intel Broadwell
Benchmark:
Crypto Benchmarks:
- AVX2: SHA-256 50 megs took 0.320 seconds, 156.118 MB/s
Cycles per byte = 9.75 = 47% - AVX1: SHA-256 50 megs took 0.272 seconds, 184.068 MB/s
Cycles per byte = 11.89 = 39% - Normal: SHA-256 50 megs took 0.376 seconds, 132.985 MB/s
Cycles per byte = 16.46 - AVX2: SHA-384 50 megs took 0.226 seconds, 221.318 MB/s
Cycles per byte = 6.88 = 42% - AVX1: SHA-384 50 megs took 0.192 seconds, 260.975 MB/s
Cycles per byte = 8.39 = 9% - Normal: SHA-384 50 megs took 0.209 seconds, 239.743 MB/s
Cycles per byte = 9.13 - AVX2: SHA-512 50 megs took 0.224 seconds, 223.120 MB/s
Cycles per byte = 6.82 = 75% - AVX1: SHA-512 50 megs took 0.188 seconds, 266.126 MB/s
Cycles per byte = 8.22 = 50% - Normal: SHA-512 50 megs took 0.281 seconds, 177.997 MB/s
Cycles per byte = 12.29
Reference
Platform:
Atmel SAMD21
ARM Cortex M0
48 MHz
Benchmark:
TLS Establishment Times:
Hardware accelerated ATECC508A: 2.342 seconds average
Software only: 13.422 seconds average
The TLS connection establishment time is 5.73 times faster with the ATECC508A.
Software only implementation (SAMD21 48Mhz Cortex-M0, Fast Math TFM-ASM):
ECC 256 key generation 3123.000 milliseconds, avg over 5 iterations
EC-DHE key agreement 3117.000 milliseconds, avg over 5 iterations
EC-DSA sign time 1997.000 milliseconds, avg over 5 iterations
EC-DSA verify time 5057.000 milliseconds, avg over 5 iterations
ATECC508A HW accelerated implementation:
ECC 256 key generation 144.400 milliseconds, avg over 5 iterations
EC-DHE key agreement 134.200 milliseconds, avg over 5 iterations
EC-DSA sign time 293.400 milliseconds, avg over 5 iterations
EC-DSA verify time 208.400 milliseconds, avg over 5 iterations
For reference the benchmarks for RNG, AES, MD5, SHA and SHA256 are:
RNG 25 kB took 0.784 seconds, 0.031 MB/s (coming from the ATECC508A)
AES 25 kB took 0.177 seconds, 0.138 MB/s
MD5 25 kB took 0.050 seconds, 0.488 MB/s
SHA 25 kB took 0.141 seconds, 0.173 MB/s
SHA-256 25 kB took 0.352 seconds, 0.069 MB/s
Reference
Microchip Hardware-TLS Platform
wolfSSL Microchip ATECC508A Overview and Examples
Platform:
STM32F221G-EVAL
ARM Cortex M3
120MHz
1 MB FLASH
128 KB SRAM
Benchmark:
Crypto Benchmarks:
Software Crypto: wolfCrypt Benchmark, Normal Big Integer Math Library
AES 1024 kB took 0.822 seconds, 1.22 MB/s
ARC4 1024 KB took 0.219 seconds, 4.57 MB/s
DES 1024 KB took 1.513 seconds, 0.66 MB/s
3DES 1024 KB took 3.986 seconds, 0.25 MB/s
MD5 1024 KB took 0.119 seconds, 8.40 MB/s
SHA 1024 KB took 0.279 seconds, 3.58 MB/s
SHA-256 1024 KB took 0.690 seconds, 1.45 MB/s
RSA 2048 encryption took 111.17 milliseconds, avg over 100 iterations
RSA 2048 decryption took 1204.77 milliseconds, avg over 100 iterations
DH 2048 key generation 467.90 milliseconds, avg over 100 iterations
DH 2048 key agreement 538.94 milliseconds, avg over 100 iterations
STM32F2 Hardware Crypto: wolfCrypt Benchmark, Normal Big Integer Math Library
AES 1024 kB took 0.105 seconds, 9.52 MB/s
ARC4 1024 KB took 0.219 seconds, 4.57 MB/s
DES 1024 KB took 0.125 seconds, 8.00 MB/s
3DES 1024 KB took 0.141 seconds, 7.09 MB/s
MD5 1024 KB took 0.045 seconds, 22.22 MB/s
SHA 1024 KB took 0.047 seconds, 21.28 MB/s
SHA-256 1024 KB took 0.690 seconds, 1.45 MB/s
RSA 2048 encryption took 111.09 milliseconds, avg over 100 iterations
RSA 2048 decryption took 1204.88 milliseconds, avg over 100 iterations
DH 2048 key generation 467.56 milliseconds, avg over 100 iterations
DH 2048 key agreement 542.11 milliseconds, avg over 100 iterations
Reference
Platform:
Texas Instruments
Tiva C Series TM4C1294XL Connected Launchpad
(www.ti.com)
ARM Cortex-M4
120 MHz
1 MB FLASH
256 KB SRAM
6 KB EEPROM
Benchmark:
Crypto Benchmarks:
AES 25 kB took 0.038 seconds, 0.642 MB/s
Camellia 25 kB took 0.032 seconds, 0.763 MB/s
ARC4 25 kB took 0.006 seconds, 4.069 MB/s
RABBIT 25 kB took 0.005 seconds, 4.883 MB/s
CHACHA 25 kB took 0.007 seconds, 3.488 MB/s
3DES 25 kB took 0.164 seconds, 0.149 MB/s
MD5 25 kB took 0.003 seconds, 8.138 MB/s
POLY1305 25 kB took 0.004 seconds, 6.104 MB/s
SHA 25 kB took 0.006 seconds, 4.069 MB/s
SHA-256 25 kB took 0.014 seconds, 1.744 MB/s
SHA-512 25 kB took 0.042 seconds, 0.581 MB/s
RSA 2048 encryption took 88.000 milliseconds, avg over 1 iterations
RSA 2048 decryption took 1456.000 milliseconds, avg over 1 iterations
DH 2048 key generation 661.000 milliseconds, avg over 1 iterations
DH 2048 key agreement 665.000 milliseconds, avg over 1 iterations
ECC 256 key generation 130.400 milliseconds, avg over 5 iterations
EC-DHE key agreement 118.000 milliseconds, avg over 5 iterations
EC-DSA sign time 136.800 milliseconds, avg over 5 iterations
EC-DSA verify time 253.800 milliseconds, avg over 5 iterations
Reference
Platform:
Freescale TWR-K70F120M
(www.freescale.com)
Freescale Kinetis K70
120 MHz
2 GB FLASH
1 GB RAM
Benchmark:
Crypto Benchmarks:
AES 5120 kB took 9.059 seconds, 0.55 MB/s
ARC4 5120 kB took 2.190 seconds, 2.28 MB/s
DES 5120 kB took 18.453 seconds, 0.27 MB/s
MD5 5120 kB took 1.396 seconds, 3.58 MB/s
SHA 5120 kB took 3.635 seconds, 1.38 MB/s
SHA-256 5120 kB took 9.145 seconds, 0.55 MB/s
RSA 2048 encryption took 73.99 milliseconds, avg over 100 iterations
RSA 2048 decryption took 1359.09 milliseconds, avg over 100 iterations
DH 2048 key generation 536.75 milliseconds, avg over 100 iterations
DH 2048 key agreement 540.99 milliseconds, avg over 100 iterations
Build Details
- MQX RTOS, using the fastmath library with TFM_TIMING_RESISTANT
- FREESCALE_MQX define set in <cyassl_root>/cyassl/ctaocrypt/settings.h
- CodeWarrior 10.2 IDE and compiler, optimizing for speed
Reference
Freescale TWR-K70F120M: http://www.freescale.com/webapp/sps/site/prod_summary.jsp?code=TWR-K70F120M
Platform:
Apple TV 2
(www.apple.com)
Apple A4 (ARM Cortex-A8)
1 GHz
8 GB FLASH
256 MB RAM
Benchmark:
Crypto Benchmarks:
AES 5 megs took 0.500 seconds, 9.99 MB/s
ARC4 5 megs took 0.174 seconds, 28.66 MB/s
RABBIT 5 megs took 0.126 seconds, 39.56 MB/s
3DES 5 megs took 2.196 seconds, 2.28 MB/s
MD5 5 megs took 0.163 seconds, 30.73 MB/s
SHA 5 megs took 0.137 seconds, 36.61 MB/s
SHA-256 5 megs took 0.309 seconds, 16.20 MB/s
RSA 1024 encryption took 1.12 milliseconds, avg over 100 iterations
RSA 1024 decryption took 17.81 milliseconds, avg over 100 iterations
DH 1024 key generation 11.90 milliseconds, avg over 100 iterations
DH 1024 key agreement 11.22 milliseconds, avg over 100 iterations
Build Details
Complete build, compiled with fastmath (--enable-fastmath)
Reference
Blog Post: Running CyaSSL on the Apple TV 2
Benchmark:
Memory Usage:
RAM Usage: 2.0 kB
Flash Usage*: 64 kB
* This included our test driver code, about 3kB.
Crypto Benchmarks:
public RSA: 10 milliseconds
private RSA: 165 milliseconds
Build Details
- Complete build, everything but SHA-512, DH, DSA, and HC-128
- Compiled using mbed cloud compiler
Reference
http://mbed.org/users/toddouska/libraries/CyaSSL/lm43pv
http://mbed.org/users/toddouska/programs/cyassl-client/lm394s
Relative Cipher Performance
Although the performance of individual ciphers and algorithms will depend on the host platform, the following graph shows relative performance between some of wolfCrypt’s algorithms. These tests were conducted on a Macbook Pro (OS X 10.6.8) running a 2.2 GHz Intel Core i7.

If you want to use only a subset of ciphers, you can customize which specific cipher suites and/or ciphers wolfSSL uses when making an SSL/TLS connection. For example, to force 128-bit AES, add the following line after the call to wolfSSL_CTX_new (SSL_CTX_new):
wolfSSL_CTX_set_cipher_list(ctx, “AES128-SHA”);
Benchmarking Notes
-
The processors native register size (32 vs 64-bit) can make a big difference when doing 1000+ bit public key operations.
-
fastmath (--enable-fastmath) reduces dynamic memory usage and speeds up public key operations. If you are having trouble building on a 32-bit platform with fastmath, disable shared libraries so that PIC isn’t hogging a register (also see notes in the README):
./configure --enable-fastmath --disable-shared
make clean
make*NOTE: doing a “make clean” is good practice with wolfSSL when switching configure options
-
By default, fastmath tries to use assembly optimizations if possible. If assembly optimizations don’t work, you can still use fastmath without them by adding TFM_NO_ASM to CFLAGS when building wolfSSL:
./configure --enable-fastmath CFLAGS=-DTFM_NO_ASM
-
Using fasthugemath can try to push fastmath even more for users who are not running on embedded platforms:
./configure --enable-fasthugemath
-
With the default wolfSSL build, we have tried to find a good balance between memory usage and performance. If you are more concerned about one of the two, please see Chapter 2 of the wolfSSL manual for additional wolfSSL configuration options.
-
Bulk Transfers: wolfSSL by default uses 128 byte I/O buffers since about 80% of SSL traffic falls within this size and to limit dynamic memory use. It can be configured to use 16K buffers (the maximum SSL size) if bulk transfers are required.
Publications and Flyers
Publications in relation to benchmarking our SSL/TLS and crypto libraries:

wolfSSL+NTRU: High-Performance SSL
This flyer details the performance gains that can be seen when using the wolfSSL embedded SSL library with Security Innovation’s NTRU cipher. NTRU is similar to the RSA public key algorithm but can offer anywhere from a 20-200X speed improvement.

wolfSSL Secure memcached Benchmarks
Because wolfSSL can offer fast encryption and low memory usage it can easily be leveraged onto high-volume servers supporting many thousands of connections. This flyer demonstrates memcached benchmarks using wolfSSL.